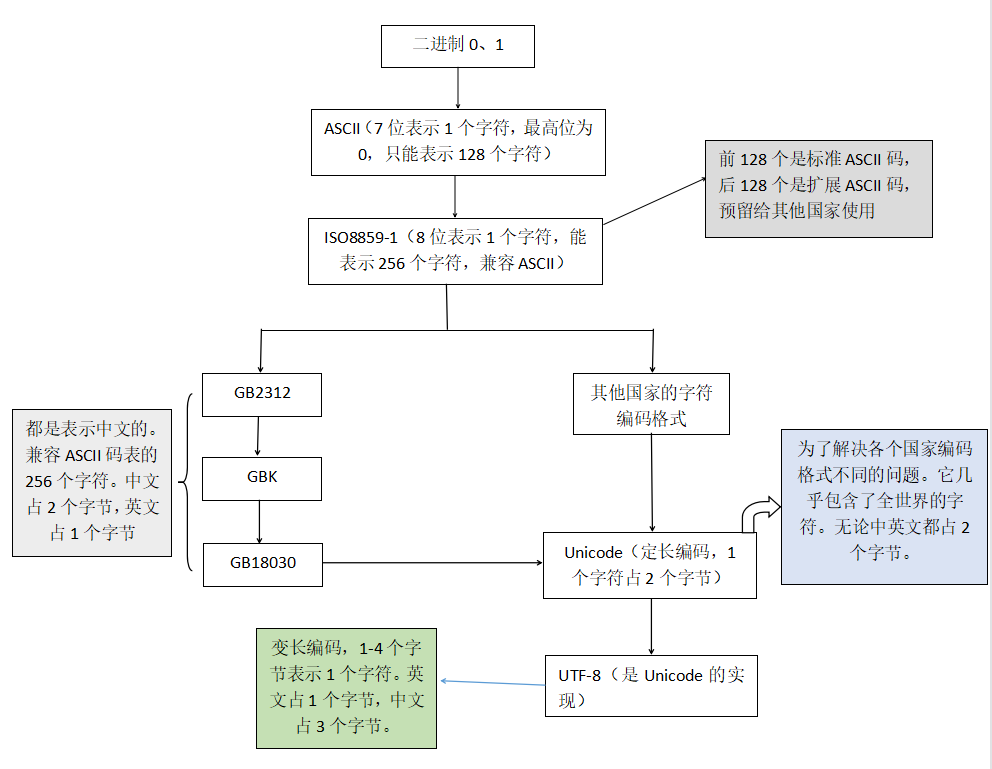


常用的编码格式:ASCII、GBK、UTF-8、Unicode
python解释器使用的是Unicode,.py文件在磁盘上使用UTF-8存储。
计算机中的数据都是以二进制形式(0/1)存储的,在计算机中最小的单位是位(bit)
1bytes = 8bit (bytes是字节,简写为B)
1KB = 1024bytes
1MB = 1024KB
1GB = 1024MB
1TB = 1024GB ……
编码格式
![图片[1]-Python字符串的编码与解码以及常见编码格式-尤尤'blog](https://pic.yxfseo.cn/wp-content/uploads/2023/10/20231019113122262-31f79dcf10c6863f6a6408f72e21de4.png?imageView2/0/interlace/1/q/75|imageslim)
1、ASCII
计算机只能识别0或者1,这并不好记,所以就编成了ASCII码表,在ASCII码表中,用1个字节表示一个字符。
在python中可以使用 ord() 和 chr() 方法进行转换:
# 将字符转换成对应的ASCII码值
print(ord('A')) # 65
# 将数字转换成ASCII码表中对应的字符
print(chr(97)) # aASCII表中共有256个字符。前128个位置对应现实生活中的128中符号,后128个预留给其他国家使用,称为扩展ASCII码。
2、GBK/GB2312/GB18030
GB2312:在1980年推出的,可以表示简体中文。这里面共有7445个字符,但仍然不够使用。
GBK:1995年推出,不仅可以表示简体中文,还可以表示繁体中文。中文占2个字节
GB18030:可以表示27484个字符,不仅可以表示简体中文、繁体中文,可以表示少数民族文字的字符。采用变长多字节编码,每个字可以由1个、2个或4个字节组成。
3、Unicode
为了解决各个国家编码冲突的问题,就产生了Unicode编码,它几乎包含了全世界的字符。在Unicode中无论英文还是中文都用2个字节表示。
4、UTF-8
UTF-8是针对Unicode的一种可变长度字符编码。规定英文用1个字节表示,其中中文占3个字节。
编码与解码
1)编码:将字符串转换成二进制数据(bytes)。
通过 encode() 方法进行编码。
# GBK中一个中文占两个字节
# 转换成GBK编码格式
print('你好'.encode('GBK')) # b'\xc4\xe3\xba\xc3'
print(bytes('你好','GBK')) # b'\xc4\xe3\xba\xc3'
# GBK中一个中文占三个字节
# 转换成UTF-8编码格式
print('你好'.encode('UTF-8')) # b'\xe4\xbd\xa0\xe5\xa5\xbd'
print(bytes('你好','UTF-8')) # b'\xe4\xbd\xa0\xe5\xa5\xbd'2)解码:将二进制数据转换成字符串。
使用 decode() 方法进行解码。编码格式和解码格式要相同
# byte.decode('GBK') 解码,byte代表的是一个二进制数据(字节类型的数据)
byte = '你好'.encode('GBK')
print(byte,byte.decode('GBK')) # b'\xc4\xe3\xba\xc3' 你好
# 编码格式和解码格式要相同
print(b'\xe4\xbd\xa0\xe5\xa5\xbd'.decode('GBK')) #浣犲ソ 乱码了,什么格式编码就用什么格式解码
print(b'\xe4\xbd\xa0\xe5\xa5\xbd'.decode('UTF-8')) # 你好
© 版权声明
本站网络名称:
尤尤博客
本站永久网址:
https://www.yxfseo.cn
网站侵权说明:
本网站的文章部分内容可能来源于网络,仅供大家学习与参考,请在24H内删除。
1 本站一切资源不代表本站立场,并不代表本站赞同其观点和对其真实性负责。
2 本站一律禁止以任何方式发布或转载任何违法的相关信息,访客发现请向站长举报。
3 本站资源大多存储在云盘,如发现链接失效,请联系我们我们会第一时间更新。
1 本站一切资源不代表本站立场,并不代表本站赞同其观点和对其真实性负责。
2 本站一律禁止以任何方式发布或转载任何违法的相关信息,访客发现请向站长举报。
3 本站资源大多存储在云盘,如发现链接失效,请联系我们我们会第一时间更新。
THE END



暂无评论内容